
As organizations increasingly rely on cloud-based data ecosystems, the importance of data modeling in data cloud environments has grown significantly. Modern certification exams in data engineering, cloud computing, and analytics now emphasize not only theoretical understanding but also practical knowledge of how data flows, is stored, and is transformed in distributed systems.
Among the most critical topics candidates must master are data streams and data lakes. These concepts form the backbone of modern data architectures and are frequently tested in certification exams due to their relevance in real-world applications.
This article provides a comprehensive, exam-focused explanation of these concepts, helping you build both conceptual clarity and practical insight.

What is Data Modeling in a Data Cloud Environment?
Definition and Purpose
Data modeling in a data cloud environment refers to the process of structuring, organizing, and defining relationships between data elements within scalable, distributed systems. Unlike traditional database modeling, cloud-based modeling must account for high-volume, high-velocity, and diverse data types.
Key Components
Modern data cloud modeling typically includes:
- Structured data (e.g., relational tables)
- Semi-structured data (e.g., JSON, XML)
- Unstructured data (e.g., logs, images, videos)
A defining characteristic is the shift from rigid schemas to flexible approaches such as:
- Schema-on-write (data is structured before storage)
- Schema-on-read (data is structured during analysis)
Why It Matters for Exams?
Certification exams often test your ability to:
- Choose the appropriate data modeling approach
- Understand trade-offs between storage and processing
- Apply concepts to real-world scenarios

Understanding Data Streams
What Are Data Streams?
Data streams refer to the continuous flow of data generated in real time. Examples include:
- Sensor data from IoT devices
- Application logs
- Financial transactions
- User activity on websites
Unlike static datasets, streams are unbounded and constantly evolving.
Key Characteristics
- Real-time or near real-time processing
- Low latency requirements
- Event-driven architecture
- High throughput and scalability
Data Stream Processing Models
There are two main approaches:
- Real-time stream processing: Processes data instantly as it arrives
- Micro-batching: Processes small batches at frequent intervals
Understanding the distinction is crucial for exam scenarios.
Role in Data Modeling
In data modeling, streams require:
- Designing event schemas
- Managing time-based data
- Ensuring data consistency across distributed systems
They are often used in pipelines where data is ingested, transformed, and routed to storage systems such as data lakes.
Exam-Relevant Concepts
Expect questions around:
- Event structures (keys, partitions, offsets)
- Differences between streaming and batch processing
- Use cases such as fraud detection or real-time analytics
A common trap is confusing real-time ingestion with real-time processing.
Understanding Data Lakes
What is a Data Lake?
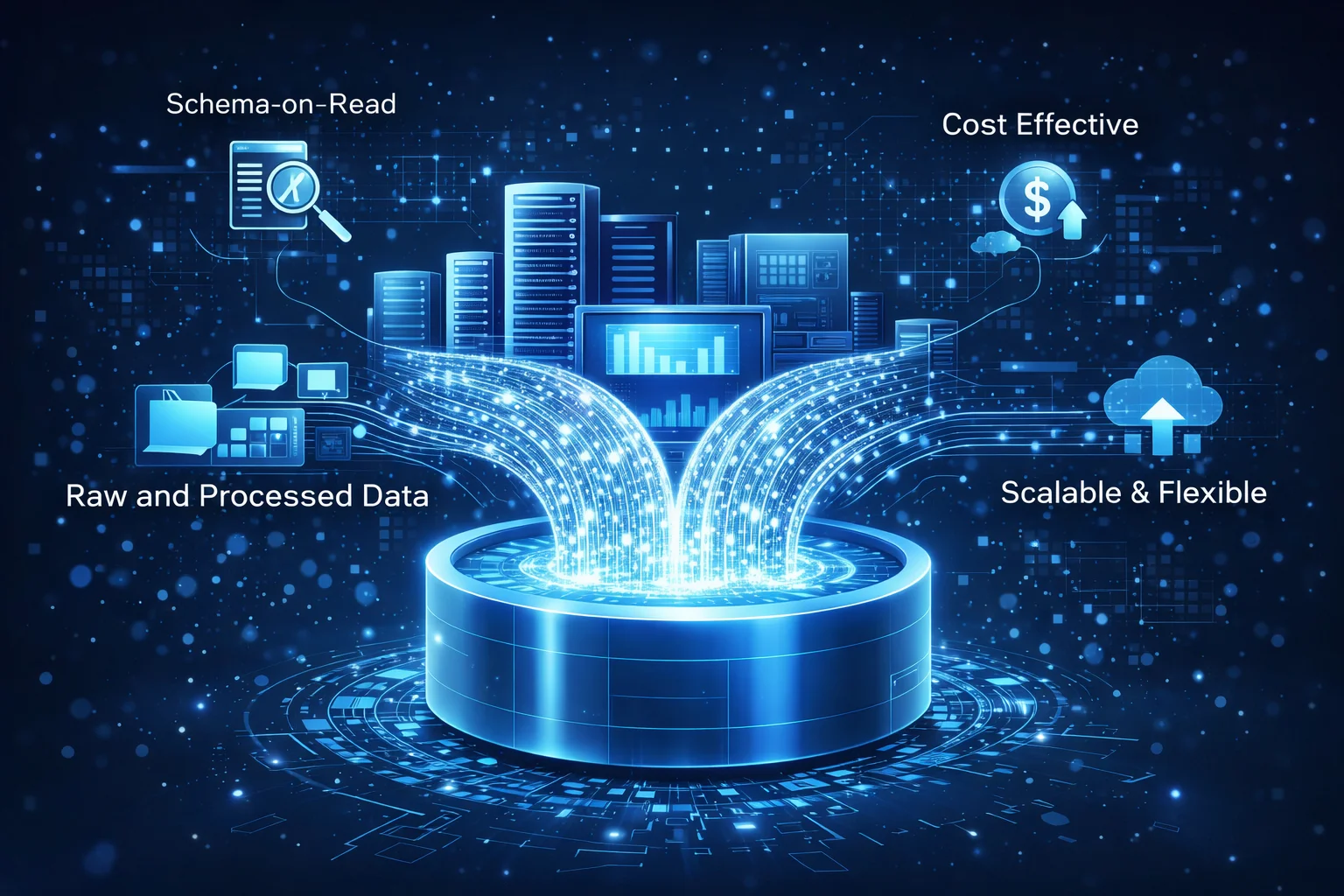
A data lake is a centralized repository that allows you to store large volumes of raw data in its native format. Unlike traditional databases, data lakes do not require predefined schemas.
Key Features
- Schema-on-read approach
- Storage of raw, processed, and curated data
- High scalability using cloud infrastructure
- Cost-effective storage solutions
Data Lake Architecture
A typical data lake consists of:
- Ingestion Layer – collects data from multiple sources
- Storage Layer – stores raw and processed data
- Processing Layer – transforms data for analytics
- Access Layer – enables querying and visualization
Role in Data Modeling
Data lakes support flexible data modeling by:
- Allowing storage of diverse data types
- Enabling transformation at the time of analysis
- Supporting advanced analytics and machine learning
Exam-Relevant Concepts
Common exam topics include:
- Differences between data lakes, data warehouses, and lakehouses
- Benefits of schema-on-read
- Data governance challenges
A frequent exam trick is testing whether candidates understand that data lakes prioritize flexibility over strict structure.
Data Streams vs Data Lakes: Key Differences
Understanding the distinction between data streams and data lakes is essential for both conceptual clarity and exam success.
| Feature | Data Streams | Data Lakes |
| Nature | Continuous data flow | Centralized storage |
| Processing | Real-time or near real-time | Batch or hybrid |
| Purpose | Data ingestion & processing | Data storage & analysis |
| Schema | Often dynamic/event-based | Schema-on-read |
In simple terms:
- Data streams move data
- Data lakes store data
Integrating Data Streams with Data Lakes
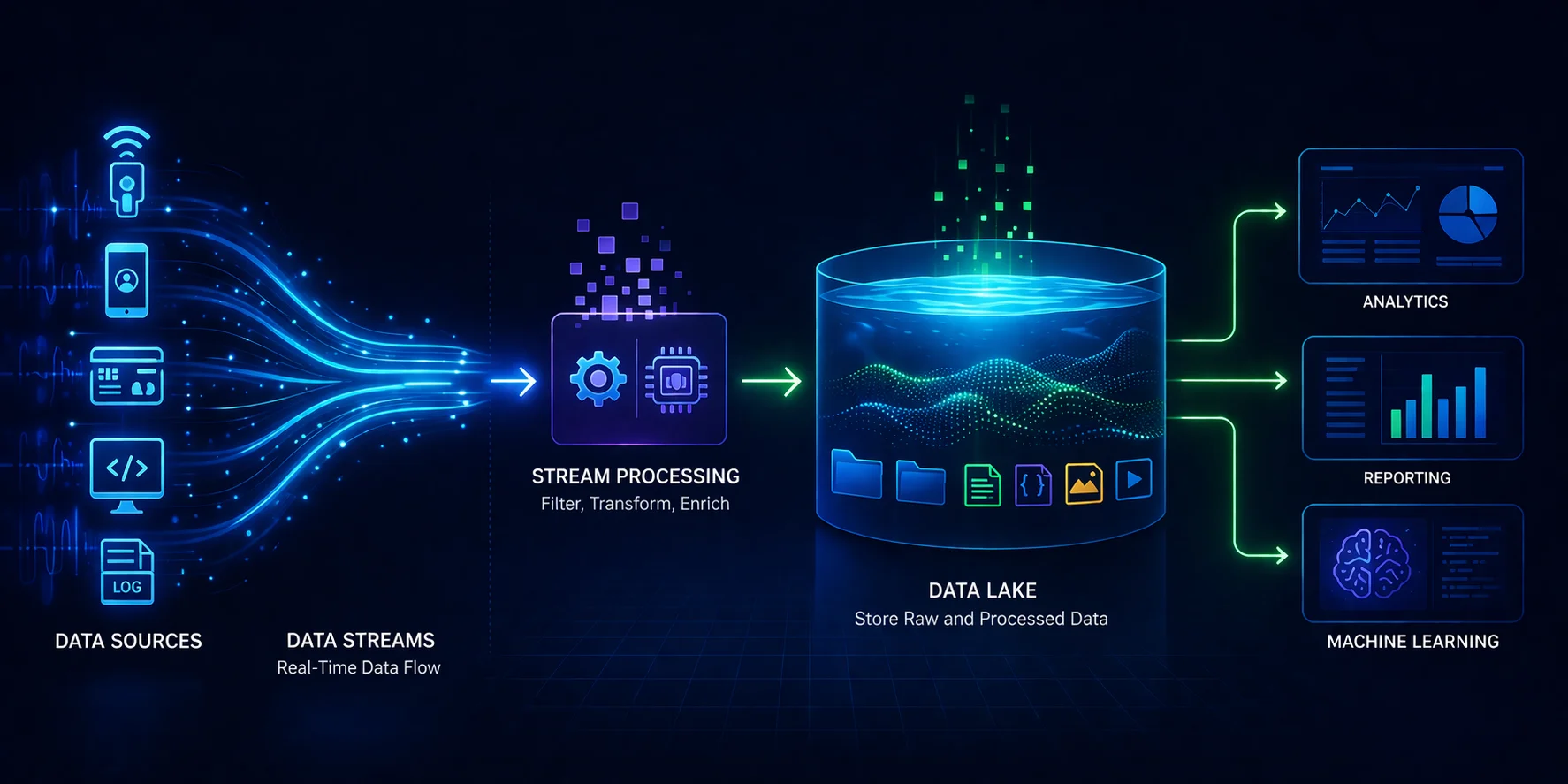
Modern Data Pipeline Architecture
In modern architectures, data streams and data lakes work together:
- Data is generated continuously (streams)
- Stream processing systems ingest and transform it
- Data is stored in data lakes for long-term analysis
This integration enables both real-time insights and historical analytics.
Lambda and Kappa Architectures
These are commonly tested frameworks:
- Lambda Architecture
- Combines batch and stream processing
- Supports both real-time and historical views
- Kappa Architecture
- Focuses on stream processing only
- Simplifies architecture by removing batch layer
Understanding when to use each is a frequent exam question.
Real-World Use Cases
- Fraud detection systems
- Customer behavior tracking
- Recommendation engines
- Operational monitoring
Common Exam Questions and Pitfalls
Candidates often lose marks due to conceptual confusion. Key pitfalls include:
- Mixing up schema-on-read vs schema-on-write
- Assuming data lakes process data in real time
- Confusing ingestion with processing
- Misinterpreting architecture-based questions
Tip:
Focus on “why” a system is used, not just “what” it is.
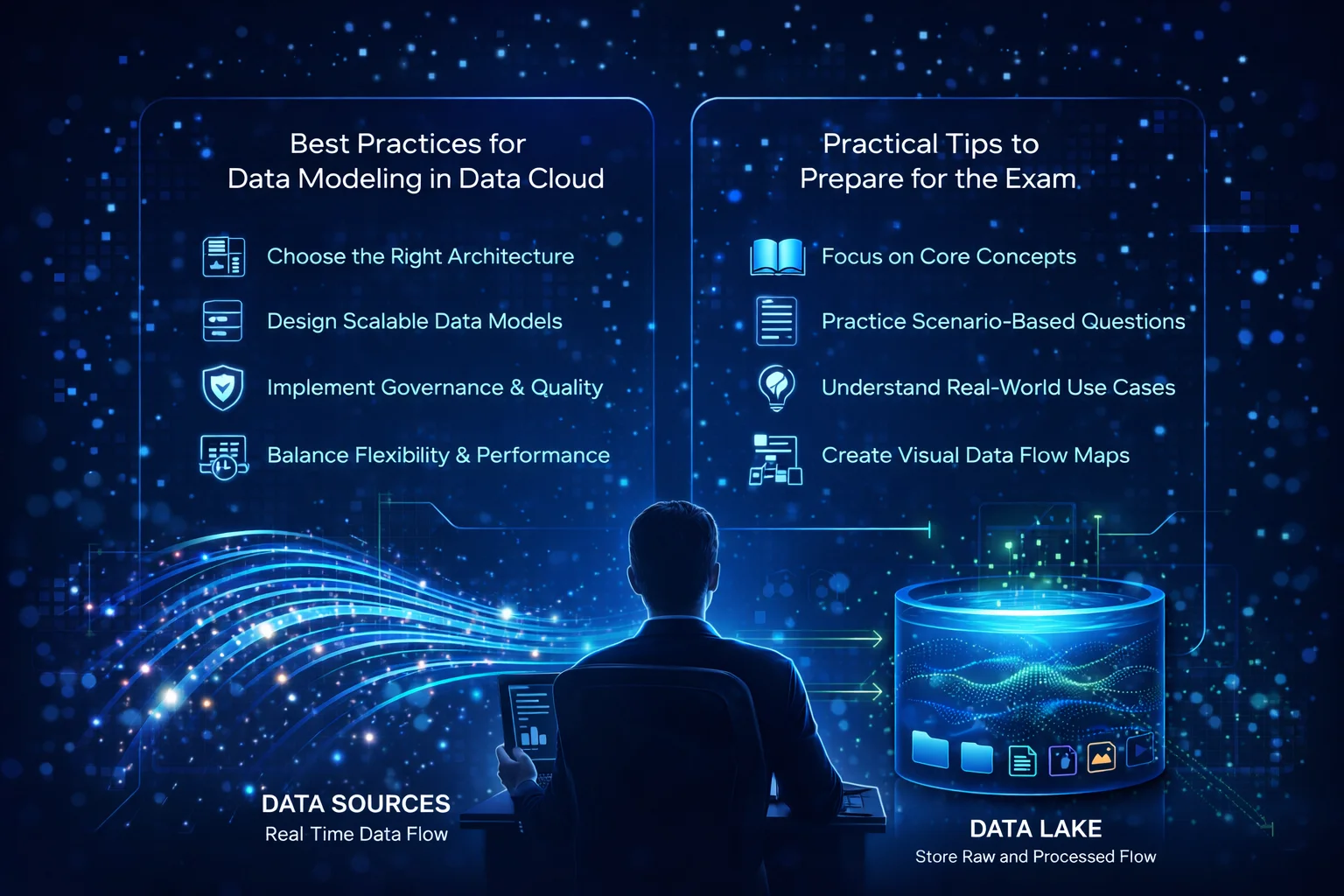
Best Practices for Data Modeling in Data Cloud
To design effective data models in cloud environments:
- Choose the right architecture (stream vs batch vs hybrid)
- Design scalable schemas for evolving data
- Implement data governance and quality checks
- Optimize for both performance and cost
Balancing flexibility with structure is key.
Practical Tips to Prepare for the Exam
- Prioritize core concepts over memorization
- Data cloud certification exam preparation course
- Practice scenario-based questions
- Understand real-world applications
- Use diagrams to visualize data flow
- Review differences between similar concepts
Consistency in revision is more effective than last-minute cramming.
Conclusion
Data modeling in the data cloud is a foundational skill for modern data professionals. A clear understanding of data streams and data lakes not only helps in passing certification exams but also prepares you for real-world data challenges.
While data streams enable real-time data movement and processing, data lakes provide scalable storage for diverse datasets. Together, they form the backbone of modern data architectures.
For exam success, focus on conceptual clarity, practical application, and architectural understanding rather than rote learning.
FAQs
What is the difference between data streams and data lakes?
Data streams handle real-time data flow, while data lakes store large volumes of data for analysis.
Why are data streams important in data modeling?
They enable real-time data ingestion and processing, which is critical for modern applications.
What does schema-on-read mean?
It means data is structured only when it is accessed, not when it is stored.
Are data lakes used for real-time processing?
No, data lakes primarily store data, although they can support near real-time analytics when integrated with streaming systems.
How are these concepts tested in exams?
Typically, through scenario-based questions that require selecting the appropriate architecture or data modeling approach.