



Salesforce-Platform-Developer-II Exam Questions With Explanations
The best Salesforce-Platform-Developer-II practice exam questions with research based explanations of each question will help you Prepare & Pass the exam!



Over 15K Students have given a five star review to SalesforceKing



Why choose our Practice Test
By familiarizing yourself with the Salesforce-Platform-Developer-II exam format and question types, you can reduce test-day anxiety and improve your overall performance.
Up-to-date Content
Ensure you're studying with the latest exam objectives and content.
Unlimited Retakes
We offer unlimited retakes, ensuring you'll prepare each questions properly.
Realistic Exam Questions
Experience exam-like questions designed to mirror the actual Salesforce-Platform-Developer-II test.
Targeted Learning
Detailed explanations help you understand the reasoning behind correct and incorrect answers.
Increased Confidence
The more you practice, the more confident you will become in your knowledge to pass the exam.
Study whenever you want, from any place in the world.

Salesforce Salesforce-Platform-Developer-II Exam Sample Questions 2026
Start practicing today and take the fast track to becoming Salesforce Salesforce-Platform-Developer-II certified.
22024 already prepared
Salesforce 2026 Release202 Questions
4.9/5.0
Given the following code: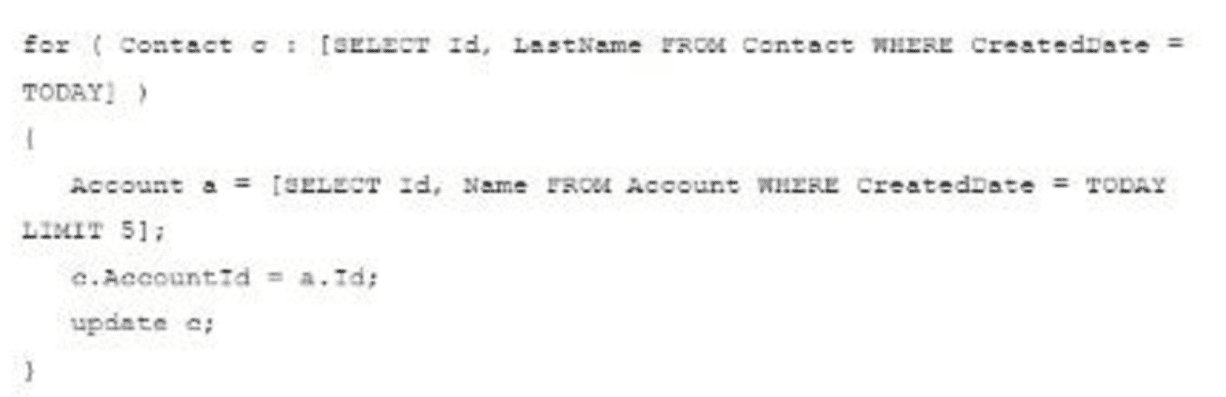
Assuming there were 10 Contacts and five Accounts created today, what is the expected
result?
A. System.QueryException: Too many DML Statement errors on Contact
B. System.QueryException: List has more than one row for Assignment on Account
C. Systemn.LimitException: Too many SOQL Queries on Account
D. System.LimitException: Too many SOQL Queries on Contact
Explanation:
🔍 Code Breakdown
for (Contact c : [SELECT Id, LastName FROM Contact WHERE CreatedDate = TODAY]) {
Account a = [SELECT Id, Name FROM Account WHERE CreatedDate = TODAY LIMIT 5];
c.AccountId = a.Id;
update c;
}
➟ The code is looping through Contacts created today.
➟ Inside the loop, it runs a SOQL query on Account with LIMIT 5, then assigns one of those accounts to the Contact.
➟ However, the result of that SOQL is not stored as a list, but in a single Account a.
🧠 Key Concept: SOQL Result Expectation
The line:
➥ Account a = [SELECT Id, Name FROM Account WHERE CreatedDate = TODAY LIMIT 5];
means the query can return up to 5 rows, but Apex is trying to store the result in a single object, not a list.
That’s a problem.
✅ Correct Answer:
B. System.QueryException: List has more than one row for assignment on Account
💥 Why?
When a SOQL query returns more than one record, and you try to assign the result to a single sObject variable, Salesforce throws a QueryException. Specifically:
➥ System.QueryException: List has more than 1 row for assignment to SObject
This happens even if you used LIMIT 5. Since the query returned more than one Account, and you're trying to assign that list of Accounts to a single Account variable, it crashes.
🧪 Let’s confirm:
10 contacts = ✅ Loop will run 10 times.
5 accounts = ✅ SOQL will return 5 rows each time.
Account a = [...] = ❌ Can't assign 5 rows to a single Account.
Consider the below trigger intended to assign the Account to the manager of the Account's region:

A. Option A
B. Option B
C. Option C
D. Option D
D. Option D
Explanation:
❌ Option A: Add if (!accountList.isEmpty()) before updating accountList
Adding a condition like if (!accountList.isEmpty()) before updating accountList is a precautionary step to ensure the list contains records before processing. This practice helps avoid null pointer exceptions or unnecessary operations if the list were unexpectedly empty. In the context of this trigger, accountList is initialized as new List
✅ Option B: Move the Region__c query outside the loop
Moving the Region__c query outside the loop is a crucial best practice to enhance performance and scalability. Currently, the trigger queries Region__c for each Account in trigger.new using anAccount.Region__Name__c, which can lead to multiple SOQL queries and potentially exceed the 100 SOQL query governor limit if more than 100 Accounts are processed. By collecting all unique Region__Name__c values into a Set
❌ Option C: Use a Map to cache the results of the Region__c query by Id
Using a Map to cache the results of the Region__c query by Id is an optimization technique to improve performance by storing query results for quick access. This approach is particularly useful when the same data might be queried multiple times or when relating records by a unique identifier like Id. However, in this trigger, the query is based on Name (from anAccount.Region__Name__c) rather than Id, so caching by Id isn’t directly applicable unless the relationship changes to a lookup field. A Map
✅ Option D: Remove the last line that updates accountList because it is not needed
Removing the last line update accountList; is essential because it’s unnecessary in a before trigger context. In before triggers, any modifications to trigger.new—such as setting anAccount.OwnerId—are automatically persisted to the database when the trigger completes, eliminating the need for an explicit DML operation. Keeping this line can lead to runtime errors, such as recursion or constraint violations, and consumes governor limits (e.g., 150 DML statements), though it’s unlikely to hit the limit here. This change simplifies the code, reduces overhead, and aligns with best practices for leveraging the implicit save behavior of before triggers. If the trigger were an after trigger, an update would be required, but given the current design, removing it is a clear improvement, making it a selected option.
Why Options B and D?
Option B addresses the critical performance issue of querying inside a loop, bulkifying the trigger to handle large datasets within governor limits, a core Salesforce best practice.
Option D eliminates redundant DML, simplifying the code and preventing potential errors, aligning with efficient trigger design.
Together, these changes optimize performance and correctness, ensuring the trigger is robust for production use.
References:
Trigger Best Practices
Governor Limits

Prep Smart, Pass Easy Your Success Starts Here!
Transform Your Test Prep with Realistic Salesforce-Platform-Developer-II Exam Questions That Build Confidence and Drive Success!

Frequently Asked Questions