Last Updated On : 29-Jun-2026
Salesforce Certified MuleSoft Platform Architect - Mule-Arch-201 Practice Test
Prepare with our free Salesforce Certified MuleSoft Platform Architect - Mule-Arch-201 sample questions and pass with confidence. Our Salesforce-MuleSoft-Platform-Architect practice test is designed to help you succeed on exam day.
Salesforce 2026
Refer to the exhibit.
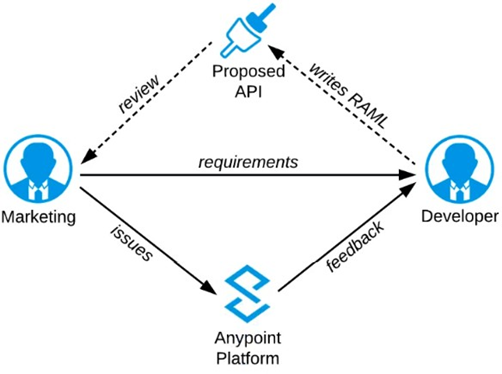
A RAML definition has been proposed for a new Promotions Process API, and has been published to Anypoint Exchange.
The Marketing Department, who will be an important consumer of the Promotions API, has important requirements and expectations that must be met.
What is the most effective way to use Anypoint Platform features to involve the Marketing Department in this early API design phase?
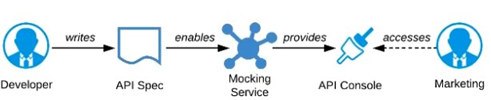
A) Ask the Marketing Department to interact with a mocking implementation of the API using the automatically generated API Console
 B) Organize a design workshop with the DBAs of the Marketing Department in which the database schema of the Marketing IT systems is translated into RAML
B) Organize a design workshop with the DBAs of the Marketing Department in which the database schema of the Marketing IT systems is translated into RAML
C) Use Anypoint Studio to Implement the API as a Mule application, then deploy that API implementation to CloudHub and ask the Marketing Department to interact with it
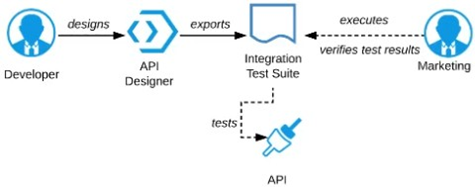
D) Export an integration test suite from API designer and have the Marketing Department execute the tests In that suite to ensure they pass
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
The Anypoint Platform emphasizes an "API-first" and "design-first" approach to development. This philosophy is specifically designed to involve stakeholders like the Marketing Department (who are typically non-technical API consumers) early in the lifecycle, before any backend code is written.
Mocking Service: When a developer publishes a RAML or OAS definition to Anypoint Exchange, the platform automatically generates documentation (API Console) and a fully functional mocking service.
Early Feedback: The Marketing Department can use this mock service via the API Console interface to simulate real API interactions, test the data models (e.g., "What does a promotion response look like?"), and provide immediate feedback on the design. This rapid feedback loop allows architects and developers to incorporate changes quickly, reducing rework later in the development process.
Analysis of Other Options
B (Design workshop with DBAs): This approach focuses too heavily on the technical, internal database schema rather than the consumer's needs or the public-facing API contract. The Marketing Department managers/users are unlikely to be DBAs, and this method does not use the platform's collaboration features effectively.
C (Implement and deploy to CloudHub): This is expensive and time-consuming. The core benefit of mocking is getting feedback before implementation and deployment.
D (Export integration test suite): The Marketing Department members are business users, not technical testers. Asking them to execute technical test suites is inappropriate and inefficient.
Key References
Anypoint Exchange: Serves as the primary mechanism for sharing API specifications and enabling early collaboration using built-in documentation and mocking capabilities.
API-first design: The methodology promotes designing the API contract first and gathering feedback via mocks to ensure the API meets consumer needs efficiently.
What Mule application can have API policies applied by
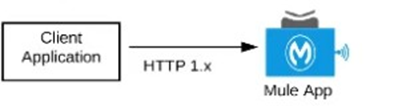
Anypoint Platform to the endpoint exposed by that Mule application?
A) A Mule application that accepts requests over HTTP/1.x
B) A Mule application that accepts JSON requests over TCP but is NOT required to provide a response
C) A Mute application that accepts JSON requests over WebSocket
D) A Mule application that accepts gRPC requests over HTTP/2
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
Anypoint Platform policies (such as Rate Limiting, Client ID Enforcement, OAuth, Spike Control, etc.) are applied through API Manager.
These policies are enforced at the API Gateway layer, which only works with Mule applications that expose endpoints over HTTP/1.x (via the HTTP Listener).
Policies cannot be applied to applications that use TCP, WebSocket, or gRPC over HTTP/2, because those protocols bypass the API Gateway’s policy enforcement mechanism.
❌ Why not the other options?
B. JSON over TCP → Not supported by API Manager policies. TCP endpoints don’t integrate with the API Gateway.
C. JSON over WebSocket → WebSocket connections are not supported for policy enforcement.
D. gRPC over HTTP/2 → MuleSoft does not support applying API Manager policies to gRPC endpoints.
👉 In summary:
Only Mule applications that expose HTTP/1.x endpoints can have API policies applied by Anypoint Platform.
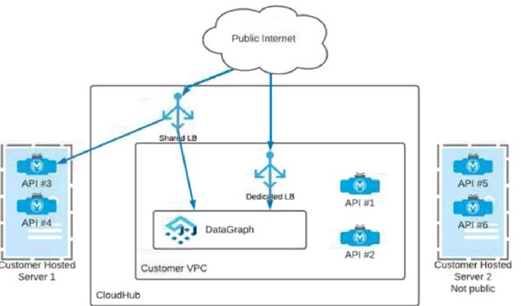
Which APIs can be used with DataGraph to create a unified schema?
A. APIs 1, 3, 5
B. APIs 2, 4 ,6
C. APIs 1, 2, s5, 6
D. APIs 1, 2, 3, 4
Explanation:
Why
To be used in Anypoint DataGraph for building a unified schema, an API must be reachable from the DataGraph runtime. In the exhibit:
API #1 and API #2 are deployed in CloudHub inside the Customer VPC. They can be reached through the Dedicated Load Balancer (DLB) that fronts the VPC-hosted CloudHub apps. That means DataGraph can invoke them securely through the VPC/DLB path.
API #3 and API #4 are on Customer Hosted Server 1, which is shown as publicly reachable (traffic can come from the public internet, and the diagram shows connectivity into the CloudHub side via the shared LB path). Because they are reachable over the network from DataGraph, they can be included in the unified schema.
API #5 and API #6 are on Customer Hosted Server 2 (Not public). Since they are explicitly marked not public and the diagram shows no private connectivity path (no VPN/Direct Connect/VPC peering/Anypoint networking link) from CloudHub/DataGraph to that server, DataGraph would not be able to reach those APIs. If an API can’t be reached, it can’t be used as a DataGraph source.
Why the other options are wrong
A (1,3,5) includes API #5, which is not publicly reachable and has no private route shown → not usable.
B (2,4,6) includes API #6, also not reachable → not usable.
C (1,2,5,6) includes API #5 and #6, neither reachable → not usable.
✅ Therefore, the APIs that can be used with DataGraph in this architecture are APIs 1, 2, 3, and 4 → Option D.
| Page 1 out of 31 Pages |