Last Updated On : 29-Jun-2026
Salesforce Certified MuleSoft Platform Architect - Mule-Arch-201 Practice Test
Prepare with our free Salesforce Certified MuleSoft Platform Architect - Mule-Arch-201 sample questions and pass with confidence. Our Salesforce-MuleSoft-Platform-Architect practice test is designed to help you succeed on exam day.
Salesforce 2026
An Order API triggers a sequence of other API calls to look up details of an order's items in a back-end inventory database. The Order API calls the OrderItems process API, which calls the Inventory system API. The Inventory system API performs database operations in the back-end inventory database.
The network connection between the Inventory system API and the database is known to be unreliable and hang at unpredictable times.
Where should a two-second timeout be configured in the API processing sequence so that the Order API never waits more than two seconds for a response from the Orderltems process API?
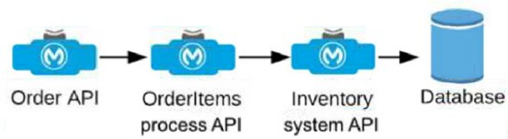
A. In the Orderltems process API implementation
B. In the Order API implementation
C. In the Inventory system API implementation
D. In the inventory database
Explanation:
The SLA Requirement: The requirement is that the Order API never waits more than two seconds for a response from the OrderItems Process API.
Controlling the Wait Time: To guarantee this, the Order API must set a response timeout on its outbound HTTP request to the OrderItems Process API.
Point of Enforcement: In MuleSoft, the HTTP Request connector is where you specify how long the current flow should block while waiting for a response. Setting this to 2,000 ms (2 seconds) in the Order API ensures that if the downstream chain (Process API → System API → Database) hangs, the Order API will stop waiting and can take corrective action (like returning an error or a fallback response).
Downstream Issues: Since the connection between the System API and the database is known to be unreliable and "hangs," any timeout set further down the chain (e.g., in the System API) would only help the System API, not the Order API. If the System API's timeout is higher than 2 seconds, the Order API would still be left waiting beyond its limit.
🔴 Incorrect Answers
A. In the OrderItems Process API: Configuring a timeout here would control how long the Process API waits for the System API. It does not prevent the Order API from waiting indefinitely if the Process API itself hangs or has a longer timeout.
C. In the Inventory System API: This would protect the System API from a hanging database, but it does not account for potential latency or hangs within the OrderItems Process API layer.
D. In the inventory database: Database timeouts are a last resort. While good for resource management on the DB server, they are often set to much longer durations (e.g., 30–60 seconds) and cannot guarantee the specific 2-second SLA required by the top-level Order API.
📚 Reference
MuleSoft Documentation: HTTP Request Connector Response Timeout
Key Concept:
Fail Fast. In a distributed architecture, each consumer is responsible for its own uptime and performance. By setting a timeout at the "top" of the chain (Order API), you ensure that the end-user experience is protected from downstream unreliability.
| Salesforce-MuleSoft-Platform-Architect Exam Questions - Home |
| Page 2 out of 31 Pages |