



Salesforce-MuleSoft-Platform-Architect Exam Questions With Explanations
The best Salesforce-MuleSoft-Platform-Architect practice exam questions with research based explanations of each question will help you Prepare & Pass the exam!



Over 15K Students have given a five star review to SalesforceKing



Why choose our Practice Test
By familiarizing yourself with the Salesforce-MuleSoft-Platform-Architect exam format and question types, you can reduce test-day anxiety and improve your overall performance.
Up-to-date Content
Ensure you're studying with the latest exam objectives and content.
Unlimited Retakes
We offer unlimited retakes, ensuring you'll prepare each questions properly.
Realistic Exam Questions
Experience exam-like questions designed to mirror the actual Salesforce-MuleSoft-Platform-Architect test.
Targeted Learning
Detailed explanations help you understand the reasoning behind correct and incorrect answers.
Increased Confidence
The more you practice, the more confident you will become in your knowledge to pass the exam.
Study whenever you want, from any place in the world.

Salesforce Salesforce-MuleSoft-Platform-Architect Exam Sample Questions 2026
Start practicing today and take the fast track to becoming Salesforce Salesforce-MuleSoft-Platform-Architect certified.
21524 already prepared
Salesforce 2026 Release152 Questions
4.9/5.0
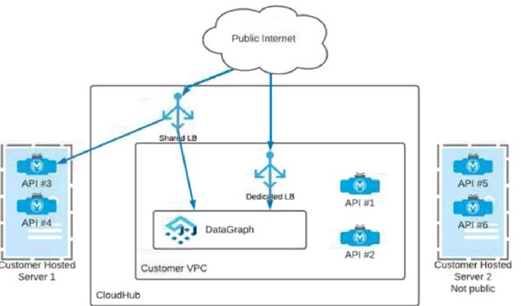
Which APIs can be used with DataGraph to create a unified schema?
A. APIs 1, 3, 5
B. APIs 2, 4 ,6
C. APIs 1, 2, s5, 6
D. APIs 1, 2, 3, 4
Explanation:
Why
To be used in Anypoint DataGraph for building a unified schema, an API must be reachable from the DataGraph runtime. In the exhibit:
API #1 and API #2 are deployed in CloudHub inside the Customer VPC. They can be reached through the Dedicated Load Balancer (DLB) that fronts the VPC-hosted CloudHub apps. That means DataGraph can invoke them securely through the VPC/DLB path.
API #3 and API #4 are on Customer Hosted Server 1, which is shown as publicly reachable (traffic can come from the public internet, and the diagram shows connectivity into the CloudHub side via the shared LB path). Because they are reachable over the network from DataGraph, they can be included in the unified schema.
API #5 and API #6 are on Customer Hosted Server 2 (Not public). Since they are explicitly marked not public and the diagram shows no private connectivity path (no VPN/Direct Connect/VPC peering/Anypoint networking link) from CloudHub/DataGraph to that server, DataGraph would not be able to reach those APIs. If an API can’t be reached, it can’t be used as a DataGraph source.
Why the other options are wrong
A (1,3,5) includes API #5, which is not publicly reachable and has no private route shown → not usable.
B (2,4,6) includes API #6, also not reachable → not usable.
C (1,2,5,6) includes API #5 and #6, neither reachable → not usable.
✅ Therefore, the APIs that can be used with DataGraph in this architecture are APIs 1, 2, 3, and 4 → Option D.

Prep Smart, Pass Easy Your Success Starts Here!
Transform Your Test Prep with Realistic Salesforce-MuleSoft-Platform-Architect Exam Questions That Build Confidence and Drive Success!
