



Salesforce-MuleSoft-Developer-II Exam Questions With Explanations
The best Salesforce-MuleSoft-Developer-II practice exam questions with research based explanations of each question will help you Prepare & Pass the exam!



Over 15K Students have given a five star review to SalesforceKing



Why choose our Practice Test
By familiarizing yourself with the Salesforce-MuleSoft-Developer-II exam format and question types, you can reduce test-day anxiety and improve your overall performance.
Up-to-date Content
Ensure you're studying with the latest exam objectives and content.
Unlimited Retakes
We offer unlimited retakes, ensuring you'll prepare each questions properly.
Realistic Exam Questions
Experience exam-like questions designed to mirror the actual Salesforce-MuleSoft-Developer-II test.
Targeted Learning
Detailed explanations help you understand the reasoning behind correct and incorrect answers.
Increased Confidence
The more you practice, the more confident you will become in your knowledge to pass the exam.
Study whenever you want, from any place in the world.

Salesforce Salesforce-MuleSoft-Developer-II Exam Sample Questions 2026
Start practicing today and take the fast track to becoming Salesforce Salesforce-MuleSoft-Developer-II certified.
2604 already prepared
Salesforce 2026 Release60 Questions
4.9/5.0
Refer to the exhibit.
What is the result if ‘’Insecure’’ selected as part of the HTTP Listener configuration?
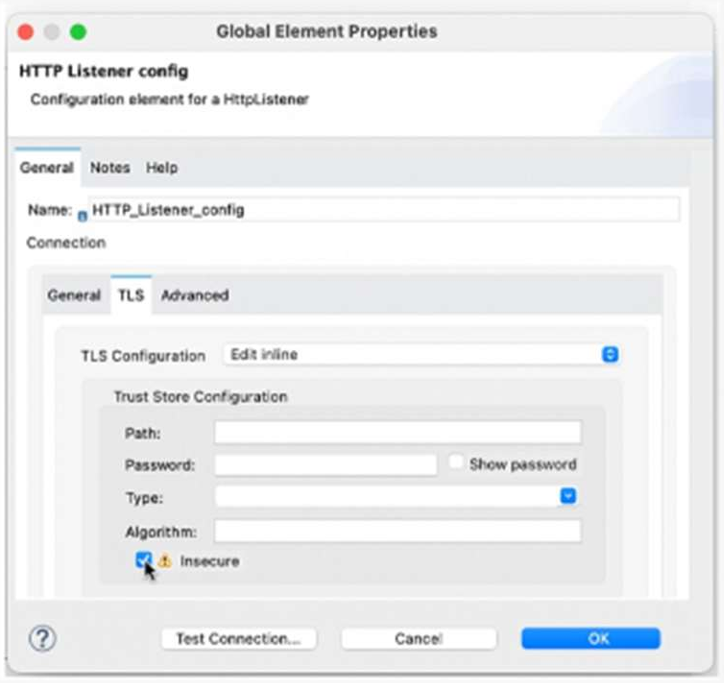
A. The HTTP Listener will trust any certificate presented by the HTTP client
B. The HTTP Lister will accept any unauthenticated request
C. The HTTP listener will only accept HTTP requests
D. Mutual TLS authentication will be enabled between this HTTP Listener and an HTTP client
Explanation:
When configuring an HTTPS Listener in MuleSoft, enabling the “Insecure” checkbox means:
The listener does not validate the client’s certificate.
It accepts any certificate, even if it’s self-signed, expired, or from an untrusted CA.
This is typically used in development or testing environments, where strict TLS validation is not required.
Why the Other Options Are Incorrect:
B. Accepts any unauthenticated request
Not accurate — it still uses HTTPS, just skips certificate validation.
C. Only accepts HTTP requests
Incorrect — “Insecure” applies to HTTPS, not HTTP.
D. Mutual TLS authentication enabled
Opposite — “Insecure” disables certificate validation, which is required for mutual TLS.
Reference:
You can read more about this in the MuleSoft HTTP Listener Configuration Guide.
Would you like to explore how to securely configure mutual TLS in MuleSoft for production environments?

Prep Smart, Pass Easy Your Success Starts Here!
Transform Your Test Prep with Realistic Salesforce-MuleSoft-Developer-II Exam Questions That Build Confidence and Drive Success!

Frequently Asked Questions