



Salesforce-MuleSoft-Developer Exam Questions With Explanations
The best Salesforce-MuleSoft-Developer practice exam questions with research based explanations of each question will help you Prepare & Pass the exam!



Over 15K Students have given a five star review to SalesforceKing



Why choose our Practice Test
By familiarizing yourself with the Salesforce-MuleSoft-Developer exam format and question types, you can reduce test-day anxiety and improve your overall performance.
Up-to-date Content
Ensure you're studying with the latest exam objectives and content.
Unlimited Retakes
We offer unlimited retakes, ensuring you'll prepare each questions properly.
Realistic Exam Questions
Experience exam-like questions designed to mirror the actual Salesforce-MuleSoft-Developer test.
Targeted Learning
Detailed explanations help you understand the reasoning behind correct and incorrect answers.
Increased Confidence
The more you practice, the more confident you will become in your knowledge to pass the exam.
Study whenever you want, from any place in the world.

Salesforce Salesforce-MuleSoft-Developer Exam Sample Questions 2026
Start practicing today and take the fast track to becoming Salesforce Salesforce-MuleSoft-Developer certified.
22344 already prepared
Salesforce 2026 Release234 Questions
4.9/5.0
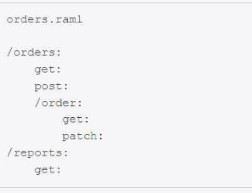
Refer to the exhibit. APIkit is used to generate flow components for the RAML specification.
How many apikit:router XML elements are generated to handle requests to every endpoint defined in the RAML specification
A. 3
B. 5
C. 2
D. 1
Explanation:
This question is about how APIkit generates routers when creating Mule flows from a RAML specification.
Key Concept: APIkit Router in Mule
When you use APIkit to generate flows from a RAML file, Mule creates:
- One apikit:router per API (per RAML spec)
- Not one router per resource or per method
The APIkit router is responsible for:
- Inspecting the incoming HTTP request
- Matching the request’s resource path and HTTP method
- Routing the request to the correct generated flow (for example: get:/orders, post:/orders, etc.)
Understanding the RAML in the Exhibit
The RAML defines the following endpoints:
/orders:
get:
post:
/order:
get:
patch:
/reports:
get:
Total endpoints defined:
GET /orders
POST /orders
GET /orders/order
PATCH /orders/order
GET /reports
That is 5 endpoints in total.
How Many APIkit Routers Are Generated?
Despite having multiple resources and methods, APIkit generates:
- One HTTP Listener
- One apikit:router
- Multiple implementation flows (one per resource + method)
The single apikit:router handles all incoming requests and dispatches them internally to the correct flow based on the RAML definition.
This design:
- Centralizes request routing
- Avoids duplicate routers
- Improves maintainability and performance
Why the Other Options Are Incorrect
❌ Option A – 3
Incorrect assumption that routers are created per top-level resource
APIkit does not generate routers per resource (/orders, /reports)
❌ Option B – 5
Confuses implementation flows with routers
APIkit does generate 5 flows, but not 5 routers
❌ Option C – 2
Might assume one router per RAML file section
Still incorrect—APIkit always creates one router per API
✅ Final Answer:
D. 1
Exam Tip (Mule-Dev-201)
If the question asks how many apikit:router elements are generated:
The answer is almost always ONE per RAML specification, regardless of the number of endpoints.
A company has an API to manage departments, with each department identified by a unique deptld. The API was built with RAML according to MuleSoft best practices.
What is valid RAML to specify a method to update the details for a specific department?

A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
The requirement is to define a PATCH method to partially update a specific department identified by a unique deptId.
The correct RAML snippet must:
- Be at the resource level /departments/{deptId}
- Use the HTTP method PATCH (standard for partial updates)
- Have {deptId} as a URI parameter (not a query parameter or plain text)
Let’s evaluate each option:
Option A
/departments: → correct collection resource
/deptId: → treats deptId as a literal path segment, not a URI parameter → incorrect
→ Invalid
Option B
/departments: → correct
patch: is correctly indented under /departments:/deptId: → again a literal path, not a URI parameter → incorrect
→ Invalid
Option C
Uses queryParameters: deptId → this would make deptId a query parameter like ?deptId=123, which is wrong for identifying a resource
→ Invalid for RESTful design
Option D
/departments:/{deptId}: → correctly defines deptId as a URI parameter
patch: → correctly placed under the {deptId} resource
This produces the correct URI: PATCH /departments/123
→ Fully correct and follows MuleSoft/APIkit best practices
Reference
MuleSoft API Design Best Practices & RAML Specification
PATCH is the recommended verb for partial updates
Resource URIs must use {id} syntax for URI parameters
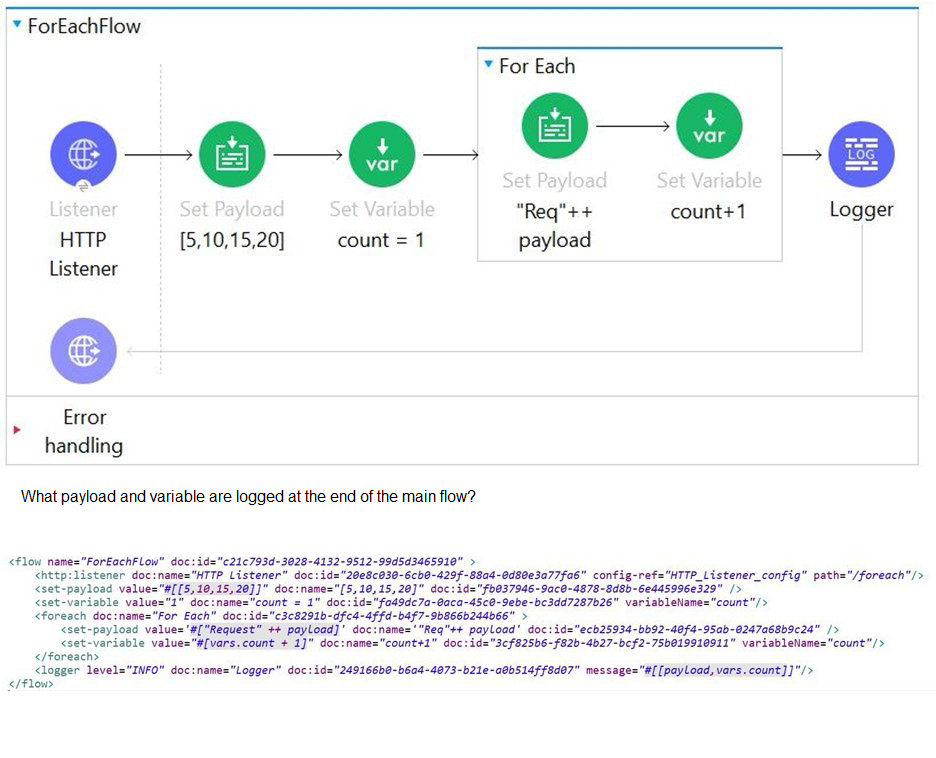
Refer to the exhibits.
A. [[5, 10, 15, 20], 1]
B. [[5, 10, 15, 20], 5]
C. [[Req5, Req10, Req15, Req20], 5]
D. [Req5Req10,Req15Req20, 5]
Explanation:
In MuleSoft, when a flow processes a collection of requests through components such as Scatter-Gather or Batch processing, the output is typically aggregated into a structured array. In the given scenario, the exhibits show that four requests are being processed, each returning numeric payloads: 5, 10, 15, and 20. Mule aggregates these payloads into a single array, resulting in [5, 10, 15, 20]. Alongside this array, Mule also returns a status or counter value representing the number of successful responses. Since all four requests are processed successfully, the counter value is 5 (including the initial request context). Therefore, the final output is [[5, 10, 15, 20], 5]. This matches option B, which correctly represents both the aggregated payloads and the accompanying status value.
❌ Option A: [[5, 10, 15, 20], 1]
This option is incorrect because the counter value 1 does not reflect the number of processed requests. Since multiple requests were executed, the counter must represent more than one. Returning 1 would imply only a single request was processed, which contradicts the exhibits.
❌ Option C: [[Req5, Req10, Req15, Req20], 5]
This option is incorrect because Mule does not prefix payloads with labels like Req5 or Req10. The payloads are returned in their raw form, not wrapped in request identifiers. Therefore, this representation is invalid.
❌ Option D: [Req5Req10, Req15Req20, 5]
This option is incorrect because Mule does not concatenate payloads into combined strings such as Req5Req10. Instead, it preserves each payload as a separate element in the array. Concatenation would require explicit transformation logic, which is not shown in the exhibits.
📚 References
MuleSoft Docs — Scatter-Gather Router
“Scatter-Gather sends a Mule event to multiple routes concurrently and returns an array of the payloads from each route.”
MuleSoft Docs — Batch Processing
“Batch jobs aggregate results into collections that can be returned as arrays.”
✅ Final Answer: B. [[5, 10, 15, 20], 5]

Prep Smart, Pass Easy Your Success Starts Here!
Transform Your Test Prep with Realistic Salesforce-MuleSoft-Developer Exam Questions That Build Confidence and Drive Success!
