Last Updated On : 8-Jul-2026
Salesforce Certified MuleSoft Platform Integration Architect - Mule-Arch-202 Practice Test
Prepare with our free Salesforce Certified MuleSoft Platform Integration Architect - Mule-Arch-202 sample questions and pass with confidence. Our Salesforce-MuleSoft-Platform-Integration-Architect practice test is designed to help you succeed on exam day.
Salesforce 2026
Refer to the exhibit.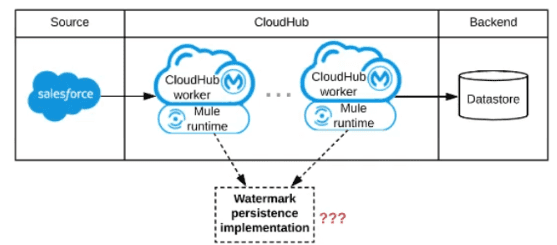
A Mule application is being designed to be deployed to several CIoudHub workers. The
Mule application's integration logic is to replicate changed Accounts from Satesforce to a
backend system every 5 minutes.
A watermark will be used to only retrieve those Satesforce Accounts that have been
modified since the last time the integration logic ran.
What is the most appropriate way to implement persistence for the watermark in order to
support the required data replication integration logic?
A. Persistent Anypoint MQ Queue
B. Persistent Object Store
C. Persistent Cache Scope
D. Persistent VM Queue
Explanation
A watermark in this context is a value (typically a timestamp) that is stored after each successful run and read at the beginning of the next run to determine which records to fetch. The key requirements for its persistence mechanism are:
Key-Value Access:
The watermark is a single, uniquely identifiable piece of data (e.g., lastModifiedDate_for_Account).
Durability:
It must survive application restarts, worker failures, and redeployments. If lost, the integration would either miss data (if the watermark is reset) or reprocess large amounts of data.
Cluster-Wide Consistency:
Since the application is deployed to several CloudHub workers, all workers must read from and write to the exact same watermark value. If each worker maintained its own watermark, they would interfere with each other, leading to missed updates or duplicates.
Let's analyze why the Object Store is the ideal choice and why the others are not:
Why B is Correct (Persistent Object Store):
The Object Store is Mule's built-in, purpose-built solution for storing key-value data that needs to be persisted and shared across a cluster.
The Persistent Object Store in CloudHub is backed by a highly available, shared database, ensuring the data is durable.
It provides a simple API (ObjectStore.put(...), ObjectStore.get(...)) that is perfect for storing and retrieving a single value like a watermark.
It is automatically shared across all workers in a CloudHub environment, guaranteeing that every instance of the application uses the same, current watermark.
Why A is Incorrect (Persistent Anypoint MQ Queue):
A queue is designed for messaging – sending discrete, consumable messages from a producer to one or more consumers.
It is not designed for storing a shared state. To use it as a watermark, you would have to consume the message (which removes it), read it, and then put it back, which is prone to race conditions and is not an atomic operation. This is a misuse of a queue's intended purpose.
Why C is Incorrect (Persistent Cache Scope):
The Cache Scope is designed to cache the response of an expensive operation (like an external API call) to improve performance.
While it can be persistent, its primary use case is for read-through caching, not for storing and updating a shared, mutable state like a watermark. Its behavior and lifecycle are not ideal for this stateful coordination pattern.
Why D is Incorrect (Persistent VM Queue):
The VM transport is designed for intra-JVM communication between flows within the same Mule runtime instance.
It is not shared across different workers/nodes in a cluster. Each CloudHub worker would have its own isolated VM queue, leading to each worker having a different watermark and causing chaos in the replication logic.
Key References
MuleSoft Documentation: Object Store
This is the definitive source, explaining its use for persistent, clustered key-value storage.
| Salesforce-MuleSoft-Platform-Integration-Architect Exam Questions - Home | Previous |
| Page 9 out of 55 Pages |