Last Updated On : 29-Jun-2026
Salesforce Certified MuleSoft Platform Architect - Mule-Arch-201 Practice Test
Prepare with our free Salesforce Certified MuleSoft Platform Architect - Mule-Arch-201 sample questions and pass with confidence. Our Salesforce-MuleSoft-Platform-Architect practice test is designed to help you succeed on exam day.
Salesforce 2026
Refer to the exhibits.
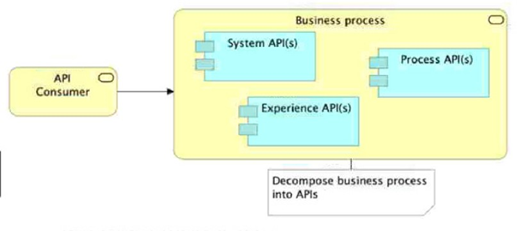
Which architectural constraint is compatible with the API-led connectivity architectural style?
A. Always use a tiered approach by creating exactly one API for each of the three layers (Experience, Process, and System)

B. Use a Process API to-orchestrate calls to multiple System APIs but not to other Process APIs:
C. Allow System APIs to return data that is not currently required by the identified Process or Experience APIs
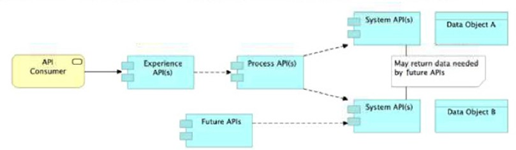
D. Handle customizations for the end-user application at the Process layer rather than at the Experience layer
Explanation:
Why B is compatible with API-led connectivity
API-led connectivity encourages clear separation of concerns across layers:
System APIs: encapsulate access to systems of record (DBs, SaaS, legacy)
Process APIs: implement business processes by orchestrating and composing data/capabilities from System APIs
Experience APIs: tailor the interface for specific consumers (web, mobile, partners)
A key architectural constraint that keeps the network clean and reusable is: Process APIs orchestrate System APIs, and you avoid building long chains of Process→Process calls unless there’s a very strong reason. That reduces coupling, prevents “process spaghetti,” and makes each Process API map cleanly to a business capability.
Why the other options are not compatible
A ❌ “Exactly one API per layer” is not API-led. Real networks have many Experience, Process, and System APIs depending on consumers and systems.
C ❌ System APIs should provide stable, reusable system access, but they should not return “extra data just in case.” That leads to overexposure, larger payloads, and weaker contracts.
D ❌ Consumer-specific customization belongs in the Experience layer, not the Process layer. Process APIs should remain consumer-agnostic to maximize reuse.
| Salesforce-MuleSoft-Platform-Architect Exam Questions - Home | Previous |
| Page 4 out of 31 Pages |