Last Updated On : 29-Jun-2026
Salesforce Certified MuleSoft Developer - Mule-Dev-201 Practice Test
Prepare with our free Salesforce Certified MuleSoft Developer - Mule-Dev-201 sample questions and pass with confidence. Our Salesforce-MuleSoft-Developer practice test is designed to help you succeed on exam day.
Salesforce 2026
Refer to the exhibits.

A company has defined this Book data type and Book example to be used in APIs. What is valid RAML for an API that uses this Book data type and Book example?
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
Understanding the Requirement
The company has already defined:
- A Book data type in a separate RAML file (BookDataType.raml)
- A Book example in a separate RAML example file (BookExample.raml)
The question asks which RAML snippet correctly uses both the data type and the example in an API definition.
In RAML 1.0, when you reuse external files:
- Data types must be imported using !include
- Examples must also be referenced using !include
- The data type should be declared under the types section
Why Option D Is Correct
Option D correctly follows RAML 1.0 syntax and best practices:
- The Book type is defined under the types section using !include BookDataType.raml
- The POST /books request body uses type: Book
- The request example correctly references the external example file using !include BookExample.raml
- The structure is valid, clean, and reusable
- This is exactly how RAML is intended to reference shared data types and named examples.
Why the Other Options Are Incorrect
❌ Option A
- References BookDataType.raml without using !include
- RAML does not automatically load external files unless explicitly included
❌ Option B
- Uses !include correctly, but defines Book outside the types section
- This makes the RAML invalid according to RAML 1.0 structure rules
❌ Option C
- References external files using paths but omits !include
- RAML requires !include to import external data types and examples
Final Conclusion
Only Option D correctly:
- Includes the external data type
- Includes the external example
- Uses proper RAML 1.0 syntax and structure
✅ Correct answer: D. Option D
📝 Mule-Dev-201 Exam Tip
For RAML reuse questions, remember this rule:
- External files → always use !include (for types, examples, traits, and libraries).
Refer to the exhibits.
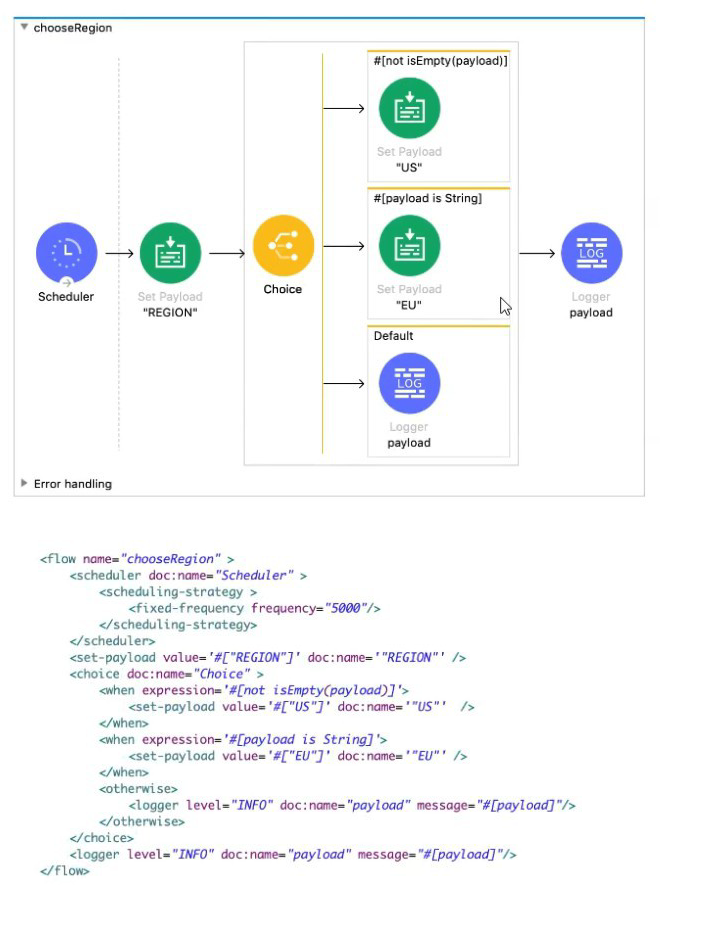
A Mule application contains a Choice router. What is logged when the flow completes?
A. EU
B. US
C. "REGION"
D. ["US", "EU"]
Explanation:
This question tests understanding of Choice router evaluation order, DataWeave expression evaluation, and the isEmpty() function behavior in Mule 4. The key insight is understanding which condition evaluates to true first and how that determines the execution path.
Step-by-Step Execution Analysis:
Initialization (Schedule Trigger):
- Flow starts via Scheduler every 5 seconds
- No incoming payload from scheduler (typically null or empty)
First Component Execution:
- Set Payload "REGION" → payload = "REGION" (a non-empty string)
Choice Router Evaluation (Order Matters!):
- First Condition: #[not isEmpty(payload)]
- payload = "REGION"
- isEmpty("REGION") returns false (string is not empty)
- not false = true
- CRITICAL: First condition evaluates to true → Choice router selects this route
First Route Execution:
- Set Payload "US" → payload = "US"
- Route completes
Choice Router Behavior:
- First-match-wins principle applies
- Second condition is NOT evaluated (short-circuit evaluation)
- otherwise route is NOT executed
Final Logger (Outside Choice Router):
- Executes after Choice router completes
- Logs current payload: "US"
Why "US" is Logged, Not "EU":
- Both conditions are technically true for payload "REGION":
- not isEmpty("REGION") = true
- "REGION" is String = true
- But order matters: Choice router executes only the first matching route
- Once first route is selected, all other routes are skipped
Why Other Options Are Incorrect:
A. EU ✗
- Would require first condition to be false and second true
- Or reverse order of conditions in Choice router
C. "REGION" ✗
- Would require both conditions to be false, triggering otherwise
- Or Choice router to not modify payload at all
D. ["US", "EU"] ✗
- Would require parallel execution (Scatter-Gather)
- Or sequential execution of both routes (not Choice router behavior)
Important DataWeave Function Details:
- isEmpty() returns true for: null, "" (empty string), [] (empty array), {} (empty object)
- isEmpty("REGION") = false because string has content
- is String type check returns true for any string value
Common Misconception:
- Many developers think "both conditions are true, so maybe both execute" or "the more specific condition should win." But Choice router is deterministic: first true condition wins, period.
Reference:
- MuleSoft Documentation - Choice Router: "Executes the first route whose condition evaluates to true"
- DataWeave Documentation - isEmpty(): Returns true for empty/null values
- Exam Domain: Processing (Understanding routing logic and expression evaluation)
- Key Concept: Choice router uses short-circuit evaluation with first-match-wins
| Salesforce-MuleSoft-Developer Exam Questions - Home | Previous |
| Page 4 out of 47 Pages |