Last Updated On : 29-Jun-2026
Salesforce Certified OmniStudio Developer - Plat-Dev-210 Practice Test
Prepare with our free Salesforce Certified OmniStudio Developer - Plat-Dev-210 sample questions and pass with confidence. Our OmniStudio-Developer practice test is designed to help you succeed on exam day.
Salesforce 2026
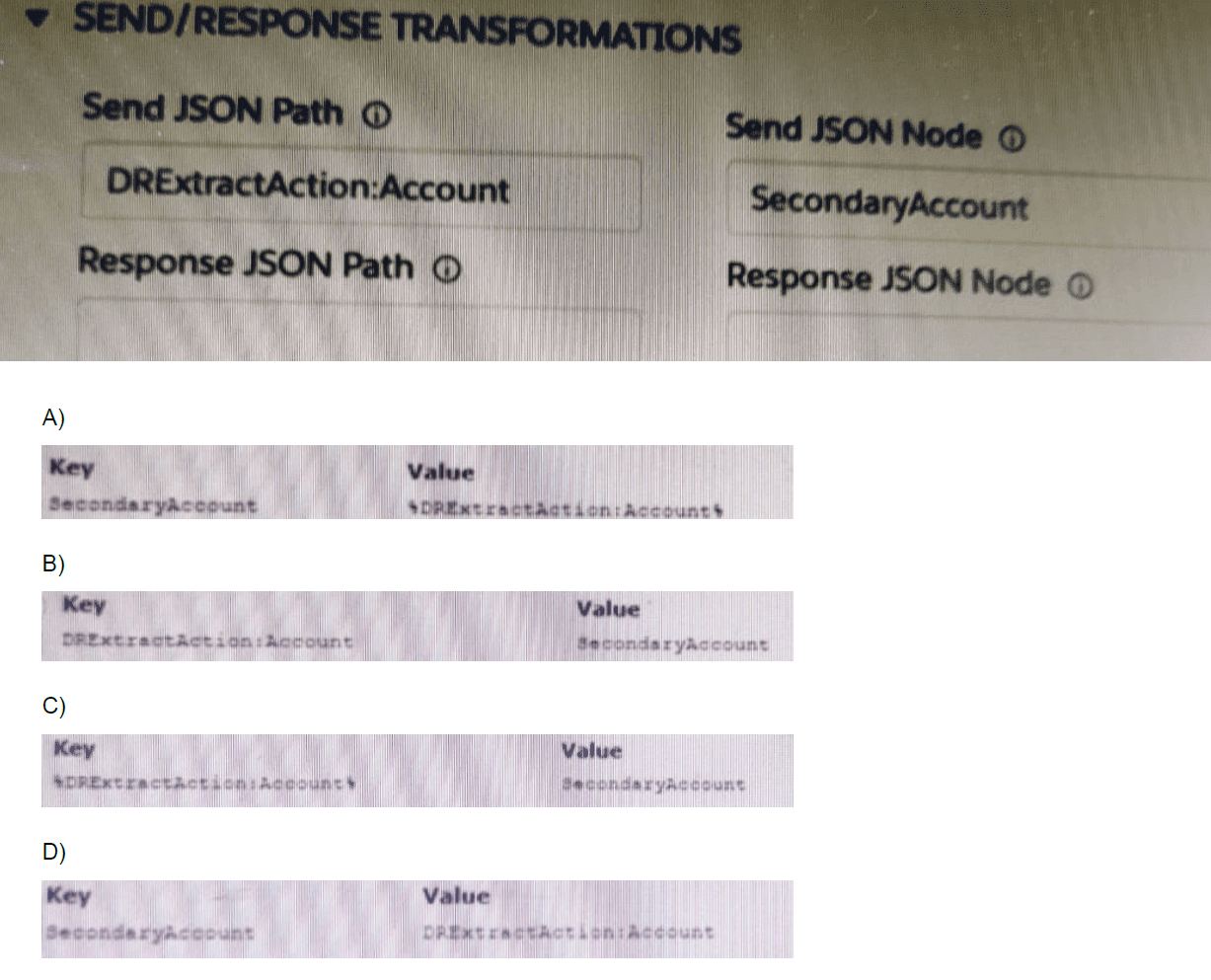
…… configure Additional input to send exactly the same data? Assume that the develop
checkedSend Only Additional input.
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
The question asks how to configure the Additional Input to send exactly the same data as the primary input, given that the "Send Only Additional Input" checkbox is selected. This means the primary "Send JSON Path" will be ignored, and only the data defined in the "Additional Input" section will be sent.
The goal is to make the "Additional Input" replicate the data that was originally going to be sent from the DRExtractAction:Account node.
Let's analyze the options in the exhibit:
Option A:
Key: SecondaryAccount
Value: DRExtractAction:Account
Analysis: This is incorrect. It creates a new node called SecondaryAccount and puts the entire contents of DRExtractAction:Account inside it. The structure sent would be { "SecondaryAccount": { ...account data... } }, which is not the same as the original flat account data.
Option B:
Key: DRExtractAction:Account
Value: SecondaryAccount
Analysis: This is incorrect. It tries to create a node named DRExtractAction:Account and populate it with the contents of a node called SecondaryAccount. However, SecondaryAccount does not exist or is not the source of the data we want to send. This would likely result in an empty or incorrect payload.
Option C:
Key: *DRExtractAction:Account
Value: SecondaryAccount
Analysis: This is incorrect. The asterisk (*) syntax is used in the Response JSON Path to extract all elements from an array. It is not standard syntax for mapping in the Additional Input section for this purpose. This configuration is invalid for replicating the object data.
Option D:
Key: SecondaryAccount
Value: DRExtractAction:Account
Analysis: This is correct. Wait, this appears identical to Option A. There must be a critical difference in the exhibit that isn't fully conveyed in the text. Let's re-analyze based on standard OmniStudio behavior.
The key is the placement of the merge field symbol #. The correct syntax to assign the value of one node to another is to use the merge field.
The correct configuration should be:
Key: SecondaryAccount
Value: #DRExtractAction:Account#
If Option D is the one that correctly uses the merge field syntax (#DRExtractAction:Account#) as the Value, while Option A uses the plain text (DRExtractAction:Account), then Option D is correct. The merge field copies the entire data structure, while the plain text would be treated as a literal string.
Reference
To clone a data node in the "Additional Input" section:
- The Key defines the name of the new node in the outgoing JSON.
- The Value must be a merge field (e.g., #OriginalNode#) that references the node you want to copy.
Therefore, the correct option is the one where the Key is the desired new node name (e.g., SecondaryAccount) and the Value is the merge field reference to the original data node (e.g., #DRExtractAction:Account#).
Based on the standard functionality and the pattern of the options, D is the correct choice, assuming it is the one that properly uses the merge field syntax to copy the data.
A developer needs to transform contact data into a JSON array.

Given the input JSON shown above, what are two ways a developer could configure a DATARaptor transform to achieve the expected Output JSON? (Choose 2 answers)
A. Use a formula LIST(Contact), and add the output of the formula as the input in the Transform tab.
B. Set the Input JSON path as List(Contact) and the OutputJSON Path as Contact.
C. Set the Input JSON Path as Contact the out JSON Path as contact and output Data type as List.
D. Set the input JSON Path as Contact and the OutPut JSON Path as List (Contact)
C. Set the Input JSON Path as Contact the out JSON Path as contact and output Data type as List.
Explanation:
A. Use a formula LIST(Contact), and add the output of the formula as the input in the Transform tab.
✅ Correct.
The LIST(Contact) formula in DataRaptor transforms takes a single object and wraps it in an array, which is exactly what we want here.
B. Set the Input JSON path as List(Contact) and the OutputJSON Path as Contact.
❌ Incorrect.
There is no valid JSON path syntax like List(Contact) in DataRaptor mappings. This would not produce the desired array structure.
C. Set the Input JSON Path as Contact, the Output JSON Path as Contact, and Output Data Type as List.
✅ Correct.
By mapping Contact → Contact and explicitly setting the Output Data Type = List, the object will be wrapped in an array at the output. This achieves the desired transformation.
D. Set the Input JSON Path as Contact and the Output JSON Path as List(Contact).
❌ Incorrect.
Again, List(Contact) is not a valid output JSON path. DataRaptor doesn’t support this as a mapping expression.
✅ Correct Answers: A and C
Key Takeaway
To convert a single object into an array in a DataRaptor Transform, you can either:
Use a LIST() formula to wrap the object, or
Map normally and change the Output Data Type to List.
Refer to the exhibit below.

What is the reason that the fields fail to display the fetched data?
A. Lookup Mode is selected in the properties of the Type Ahead Block.
B. FirstName, LastName, and BirthDate are not placed inside the Type Ahead Block.
C. The typeHead key is not in the correct format.
D. Use Data JSON is Not selected in the properties of the Type Ahead Block.
Explanation:
A Type Ahead Block in OmniScript only displays returned data if "Use Data JSON" is enabled.
When this setting is not selected, the component does not bind the fetched data to the fields such as:
- FirstName
- LastName
- BirthDate
Even if the data is successfully retrieved, the fields inside the Type Ahead Block will appear empty because the component is not instructed to use the data from the Data JSON.
Why the other answers are incorrect:
A. Lookup Mode selected
Lookup Mode does not prevent fetched data from appearing; it simply changes how the search works.
B. Fields not placed inside the Type Ahead Block
In the screenshot, they are structured under the Type Ahead container (they appear nested in the left panel).
C. TypeAhead key not in correct format
The key format would affect searching, not rendering the retrieved data.
| Page 1 out of 19 Pages |